Picture this: your AI-powered recommendation engine launches to 50,000 concurrent users on Monday morning. By Tuesday, your incident channel is flooded, not because the feature doesn’t work, but because nobody tested what happens when 12,000 users simultaneously trigger model inference during a flash sale. The scripting backlog was six sprints deep, and the last load test used a flat 200-user profile from three quarters ago.
This scenario is more common than anyone in the industry wants to admit. According to the 2024 DORA Accelerate State of DevOps Report, 75.9% of development professionals already rely on AI in their daily work [1]. Yet the same research reveals a finding that should concern every performance engineering team: AI adoption without robust testing mechanisms is actively reducing delivery stability by an estimated 7.2% for every 25% increase in AI adoption [1]. The tools and architectures are evolving faster than the testing practices designed to validate them.
This guide is not another introductory explainer. It delivers practitioner-grade guidance on AI-augmented load testing, from intelligent script generation and self-healing workflows to CI/CD-embedded performance gates and simulation strategies purpose-built for non-deterministic AI workloads. You’ll walk away with a concrete playbook for selecting the right toolchain, configuring pipeline integration, and interpreting results that drive real engineering decisions. If you’re a QA lead, SRE, or DevOps manager tired of slow scripting cycles and opaque test results, this is where the manual scripting era ends and the AI-augmented testing era begins.
- Why AI Applications Break Traditional Load Testing, and What That Costs You
- AI-Driven Automation in Load Testing: From Script Generation to Self-Healing Workflows
- Building Your CI/CD-Embedded Load Testing Pipeline: A Step-by-Step Playbook
- Simulation Strategies for AI Applications: Modeling the Unpredictable
- Selecting the Right Load Testing Toolchain: An Evaluation Framework
- Frequently Asked Questions
- Conclusion
- References and Authoritative Sources
Why AI Applications Break Traditional Load Testing, and What That Costs You
AI-powered applications introduce failure patterns that classical record-replay load testing was never architected to detect. The NIST AI Risk Management Framework (AI RMF 1.0) explicitly identifies this gap: “Difficulty in performing regular AI-based software testing, or determining what to test, since AI systems are not subject to the same controls as traditional code development” [2]. When your application’s core behavior is driven by model inference rather than deterministic business logic, the entire testing paradigm shifts.
The cost of ignoring this shift is quantifiable. DORA 2024 data shows that “the negative impact on delivery stability is larger, an estimated 7.2% reduction for every 25% increase in AI adoption” [1]. That’s not a warning about AI itself; it’s a warning about deploying AI without the testing infrastructure to match. Peer-reviewed research published in IEEE confirms that this recognition is driving active investigation into autonomous, LLM-powered load and performance testing systems as a direct response to these structural inadequacies [3].
The Non-Determinism Problem: How AI Inference Breaks Predictable Performance Curves
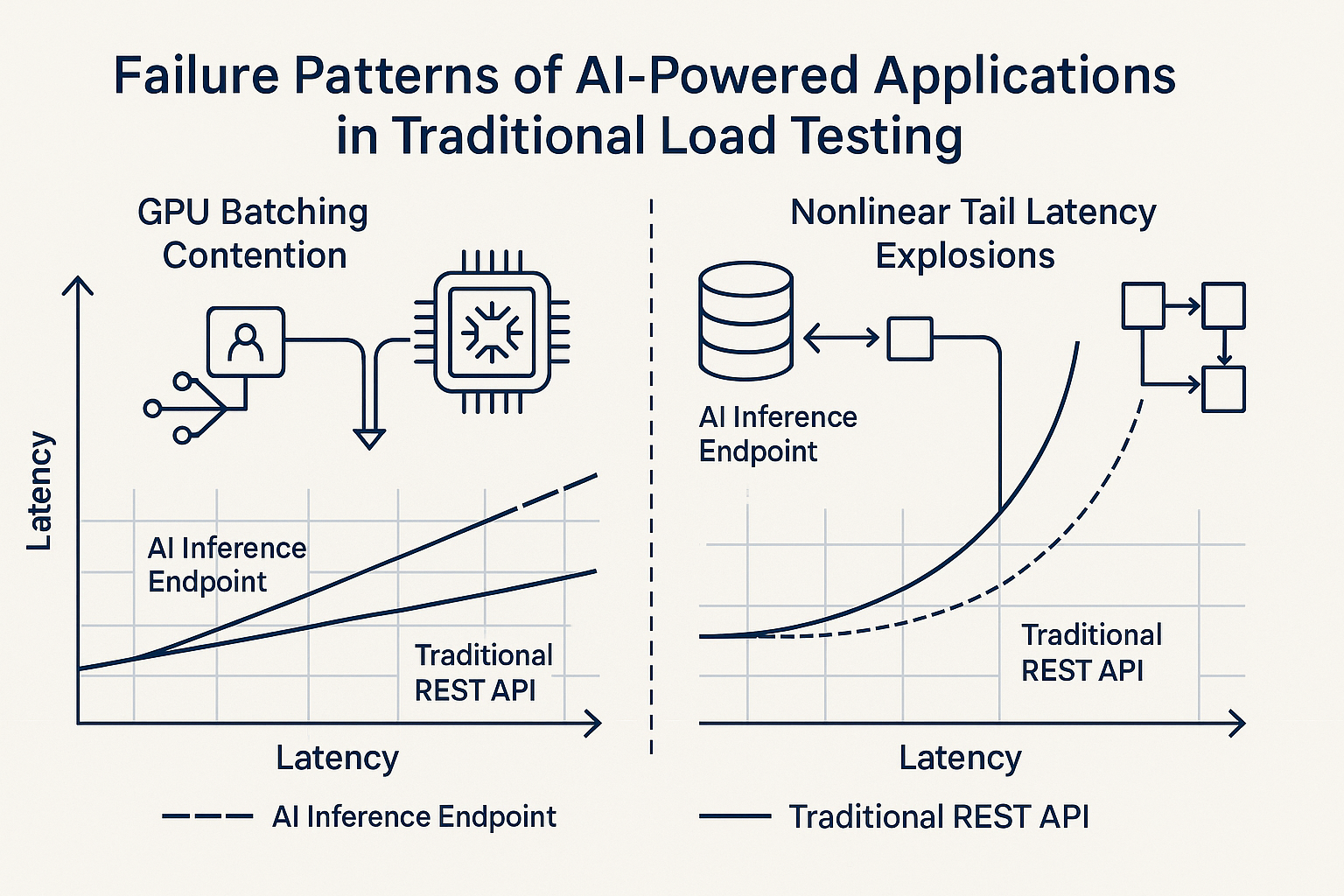
A traditional REST API that queries a relational database returns results within a narrow latency band, typically a spread of 20–40ms between p50 and p99 under load. AI inference endpoints behave nothing like this. A recommendation engine serving embeddings might report p50 = 180ms but p99 = 3,400ms under 500 concurrent users. The cause? GPU batching contention, the inference server queues requests into batches for efficient GPU utilization, but when queue depth exceeds the batch window, tail latency explodes non-linearly.
A test that reports only average response time would show 340ms and declare success. The 3,400ms p99, affecting 5 out of every 500 users on every request cycle, stays invisible until production complaints arrive. The NIST AI RMF confirms this is a categorical difference: AI software risks are fundamentally unlike traditional software risks because “underdeveloped software testing standards” cannot document AI behavior “to the standard expected of traditionally engineered software for all but the simplest of cases” [2]. For practitioners, the takeaway is concrete: if your load test dashboard doesn’t prominently surface p95 and p99 latency distributions per transaction type, as outlined in this guide to the performance metrics that matter in performance engineering, you’re flying blind on AI workloads.

The Hidden Cost of Manual Scripting Backlogs in AI-Era Delivery Cycles
When an NLP-backed chatbot endpoint changes with every model deployment, new tokenization parameters, updated context window sizes, modified response streaming behavior, manually maintained load test scripts go stale within days. A team maintaining 40+ parameterized scenarios for a microservices application with AI endpoints can easily spend 3–5 business days re-scripting after a single model version update. That’s not testing time; that’s maintenance overhead that produces zero insights.
The DORA 2024 report quantifies the gap between teams that solve this problem and teams that don’t: elite performers achieve 127x faster lead time and 2,293x faster failed deployment recovery times compared to low performers [1]. The same report finds that 56.1% of professionals responsible for test writing already rely on AI for that task [1]. The market has recognized the problem; the question is whether your toolchain has caught up.
Observability Blind Spots: Why Load Tests Pass While Production Still Burns
A load test that shows 200ms average response time tells you almost nothing if you can’t trace that latency across the API gateway, the model serving layer, and the vector database retrieval step. Without distributed tracing across AI service boundaries, engineers cannot determine whether latency is occurring at ingestion, inference, or retrieval, turning root cause analysis into a post-incident guessing game.
The second blind spot is the absence of historical baselines for anomaly comparison. If you don’t store and version your load test results alongside deployment metadata, you can’t answer the simplest regression question: “Did this model update make our p95 worse?” NIST AI RMF Section 3.1 reinforces this as a formal trustworthiness requirement: “Validity and reliability for deployed AI systems are often assessed by ongoing testing or monitoring that confirms a system is performing as intended” [2]. Continuous monitoring isn’t optional, it’s a structural prerequisite for trustworthy AI operations, and enhancing user experience with application monitoring provides a deeper look at how APM tools close this observability gap.
AI-Driven Automation in Load Testing: From Script Generation to Self-Healing Workflows
AI is transforming the three most time-consuming load testing activities: writing scripts, orchestrating execution, and maintaining test suites against changing applications. IEEE research on autonomous load and performance testing demonstrates that LLM-powered systems achieve an 80% automation rate with a 75% successful script generation rate, and 95% of system throughput analysis cases are judged acceptable by domain experts [3]. These aren’t theoretical projections, they’re measured results from a real-world cloud system study.
Intelligent Script Generation: How LLMs and AI Reduce Scripting Time by Hours
Consider a QA engineer who needs to test a user login → product search → add-to-cart → checkout flow across a 12-endpoint REST API. In a traditional workflow, they’d manually record HTTP traffic, identify dynamic parameters (session tokens, CSRF tokens, product IDs), write correlation rules, and parameterize test data, a process that typically takes 4+ hours per scenario for a mid-complexity application.
With AI-assisted script generation, the engineer provides an OpenAPI spec or HAR file. The AI parses the traffic, identifies dynamic values requiring correlation, generates parameterized scripts with extraction rules pre-applied, and produces a runnable test artifact. WebLOAD’s AI-assisted test design capabilities handle protocol complexity including authentication flows and dynamic parameter extraction that traditionally required expert JavaScript scripting knowledge. The output still needs human review, the IEEE research’s 75% success rate means roughly one in four generated scripts needs manual correction [3], but the reduction from hours to minutes per scenario fundamentally changes the testing economics. For a broader look at how AI is reshaping this space, see 5 advantages of using AI in performance testing.

Self-Healing Scripts: Keeping Your Test Suite Current When AI Apps Change Daily
Self-healing scripting addresses the maintenance problem that makes test suites go stale. When a new CSRF token field appears on a checkout form, adaptive correlation detects the new dynamic parameter and updates the extraction rule automatically. When a response payload adds a new JSON field, the script adjusts its parsing logic without manual intervention.
What self-healing doesn’t handle automatically: fundamental API endpoint renames, entirely new authentication flows, or architectural changes like migrating from REST to gRPC. These still require human review to validate the mapping. For a team maintaining 40+ scenarios, self-healing typically eliminates 60–70% of the per-sprint maintenance burden, the routine parameter drift that silently breaks scripts between deployments. NIST’s framing of ongoing monitoring as a trustworthiness requirement [2] positions this capability as part of responsible AI application governance: your test infrastructure must evolve as continuously as the systems it validates.

AI Test Orchestration: Automating Workload Profiles, Think Times, and Ramp Strategies
Beyond script creation, AI analyzes historical traffic patterns to recommend realistic workload models. Consider an e-commerce application where AI examines 30 days of production APM data and recommends a ramp from 100 to 2,000 concurrent users over 15 minutes, with a 60/30/10 split across browse/search/checkout scenarios and variable think times of 3–12 seconds per action. This differs fundamentally from a manually designed flat-load test of 500 users with uniform 5-second think times, the latter tells you nothing about how the system behaves under realistic traffic distribution.
Google’s SRE handbook establishes that realistic overload modeling is foundational to reliability engineering [4]. NIST AI 100-5 extends this principle by emphasizing that “TEVV standards would define the performance metrics for performance-based standards, which in turn allow defining what constitutes an effective risk mitigation” [5]. AI-recommended workload profiles are a concrete step toward that standardization, replacing gut-feel load profiles with data-driven simulation designs, as explored in detail in this guide on creating realistic load testing scenarios.
Building Your CI/CD-Embedded Load Testing Pipeline: A Step-by-Step Playbook
Embedding load tests in CI/CD is where testing moves from periodic activity to continuous quality gate. The CISA DevSecOps Fundamentals guidance recommends automating testing tools “across all stages of CI/CD pipelines” [6], a principle that applies as directly to performance testing as it does to security scanning. DORA 2024 confirms that “proper adherence to the basics of successful software delivery, like small batch sizes and robust testing mechanisms” [1] is a prerequisite for AI adoption to deliver positive delivery outcomes. CI/CD-embedded load testing is that robust testing mechanism.
Pre-Pipeline Readiness Checklist: 5 Things to Confirm Before You Automate Load Tests
Before writing a single pipeline configuration, confirm these five prerequisites:
- Isolated test environment. Load tests must target an environment separated from production and shared staging. Without isolation, a 2,000-VU test hammering a shared staging database corrupts test data for the functional QA team running in parallel.
- Parameterized scripts with no hardcoded values. Credentials, endpoints, and environment-specific tokens must be injected via pipeline variables, not embedded in scripts.
- SLO-based pass/fail thresholds. Define these before integration: e.g., p95 response time < 800ms for API endpoints, error rate < 1% across all transaction types under target load. Google's SRE Book establishes SLOs as the standard reliability engineering mechanism for balancing reliability with change velocity [4].
- Baseline performance snapshot. You need a known-good benchmark to compare against. Without a baseline, a p95 of 620ms means nothing, is that a regression or an improvement?
- Defined failure protocol. What happens when thresholds breach? Deployment blocked? Slack alert to the SRE channel? Automatic rollback? Decide before the first pipeline run, not during the first failure.

Configuring WebLOAD in Your Pipeline: Triggers, Thresholds, and Test Execution at Scale
A representative CI/CD integration looks like this in a Jenkins or GitHub Actions pipeline, and for a deeper dive into implementation patterns, see this guide on integrating performance testing in CI/CD pipelines:
- name: Run Load Test
run: |
webload-cli run \
--scenario ./tests/load/checkout-flow.wlp \
--vusers 500 \
--duration 600 \
--threshold-p99-latency 1200 \
--threshold-error-rate 0.5 \
--report-output ./results/
env:
TARGET_HOST: ${{ secrets.STAGING_URL }}
AUTH_TOKEN: ${{ secrets.LOAD_TEST_TOKEN }}
- name: Evaluate Results
run: |
if [ $(cat ./results/exit_code) -ne 0 ]; then
echo "Load test threshold breached — blocking deployment"
exit 1
fi
This configuration triggers on merge to main, runs 500 virtual users for 10 minutes against the checkout flow, and blocks the deployment artifact from promotion to staging if p99 latency exceeds 1,200ms or the error rate crosses 0.5%. Start with a single critical user journey before expanding to full regression suites, over-engineering the first implementation is the fastest way to get load testing removed from the pipeline entirely.
Keeping Load Tests Fast Enough for CI: Strategies for Pipeline-Friendly Test Design
Full regression load tests don’t belong in every commit gate. A tiered approach keeps feedback fast without sacrificing coverage:
| Tier | Trigger | Scenarios | Virtual Users | Duration | Threshold |
|---|---|---|---|---|---|
| Tier 1. Commit Gate | Every merge | 3 critical paths | 50 VU | 90 seconds | p95 < 1,000ms, errors < 2% |
| Tier 2. Nightly | Scheduled | 15 scenarios | 500 VU | 20 minutes | p95 < 800ms, errors < 1% |
| Tier 3. Release Gate | Pre-release | Full suite | 2,000 VU | 60 min (ramp + soak) | p95 < 600ms, errors < 0.5% |
DORA 2024’s emphasis on “small batch sizes” as a delivery performance prerequisite [1] maps directly to this strategy: smaller, faster test batches at commit time deliver faster feedback loops. SEI Carnegie Mellon’s Software Performance Engineering framework provides the academic grounding for managing performance risk at different lifecycle stages. Tier 1 catches catastrophic regressions; Tier 3 validates production readiness.
Simulation Strategies for AI Applications: Modeling the Unpredictable
AI applications introduce three simulation challenges that don’t exist in traditional web application testing, and each requires a deliberate adaptation of your test design, not just parameter tuning.
Modeling Realistic User Journeys for AI-Powered Applications
A customer service chatbot journey looks nothing like a traditional web transaction: user types greeting → AI responds with variable latency (2–8 seconds depending on context length) → user types product query → AI performs RAG lookup against a vector database → user asks follow-up → AI maintains conversational context, increasing inference time with each turn.
Translating this into a load test scenario requires at minimum three parameterized data inputs: prompt text (drawn from a corpus of 1,000+ unique queries), session ID (to maintain context state), and product category (to exercise different retrieval paths). Test assertions must focus on response time distributions and error rates per conversation turn, not on exact response content, since AI responses are non-deterministic by design. NIST AI 100-5’s TEVV framework frames this as assessing “capabilities, limitations, risks, benefits” under real-world conditions [5], which means your simulation must mirror the diversity of production behavior, not a sanitized subset.
Synthetic Test Data Generation for AI Workloads: Avoiding the Sample Bias Trap
This is where many AI load testing efforts produce dangerously optimistic results. A search AI tested with 10 repeated queries showed p95 = 120ms, because the inference server cached embeddings after the first request. When the same endpoint was tested with 10,000 unique synthetic queries, p95 rose to 890ms, a 642% difference that would have been invisible without input diversity. The cache-hit bias makes the system appear seven times faster than it actually performs under real-world query distribution.
The minimum threshold for AI inference endpoints: at least 1,000 unique input records per test scenario, with sufficient semantic variety to prevent embedding cache hits. For LLM-based applications, this means generating prompts that vary in length (50–500 tokens), topic, and complexity. The IEEE paper’s workload generation component validates this as a recognized research challenge, their 80% automation achievement in real-world cloud systems relied on representative, diverse workload inputs [3].
Selecting the Right Load Testing Toolchain: An Evaluation Framework
Rather than listing features, here’s a criteria-based evaluation framework grounded in what actually differentiates tools for AI-era load testing, and for additional guidance on weighing these factors, see how to choose a performance testing tool:
| Criterion | Open-Source Tools | SaaS Platforms | Legacy Enterprise Suites | WebLOAD |
|---|---|---|---|---|
| AI-Assisted Scripting | Community plugins, no native | Emerging, varies | Bolt-on, limited | Native AI-assisted test design |
| Protocol Coverage | HTTP-focused, extensions for others | Broad but vendor-locked | Comprehensive but complex | 80+ protocols including streaming |
| CI/CD Integration | Strong (CLI-native) | API-based, requires cloud | Complex, agent-dependent | CLI + API + native plugins |
| Cloud + On-Prem Hybrid | Self-managed only | Cloud-only | On-prem-heavy | Both, unified management |
| Correlation Engine | Manual | Semi-automated | Proprietary, tool-dependent | Intelligent, AI-enhanced |
| Analytics Depth | Basic dashboards | Vendor dashboards | Comprehensive but siloed | Real-time with anomaly detection |
| Enterprise Support | Community forums | Tiered SLAs | Expensive, bundled | Hands-on, partnership model |
RadView’s platform occupies a specific niche here: teams that need the protocol depth and enterprise reliability of legacy suites, the CI/CD-native integration of open-source tools, and AI-augmented capabilities that neither category consistently delivers. The NIST TEVV framework’s call for standardized “performance metrics for performance-based standards” [5] provides the evaluation logic, your toolchain should enable reproducible, standards-grounded performance validation, not just generate load.
Frequently Asked Questions
Is 100% load test coverage across all endpoints worth the investment?
Not always. Aiming for complete endpoint coverage often creates a maintenance burden that outweighs the risk reduction. A more effective approach: identify the 15–20% of endpoints that carry 80% of your production traffic and 100% of your revenue-critical transactions. Cover those thoroughly with parameterized, data-diverse scenarios. For remaining endpoints, monitor production APM data and add targeted load tests only when usage patterns or incident data justify it.
How do I validate that my AI load test results aren’t inflated by inference caching?
Check your unique input ratio. If your test dataset contains fewer than 500 unique prompts or queries per scenario, your results likely reflect cache performance rather than inference performance. Run two comparison tests: one with your current dataset and one with 10x the input diversity. If p95 latency differs by more than 30%, your original results have cache-hit bias. Minimum recommendation: 1,000+ unique inputs per AI inference endpoint, with semantic variety sufficient to defeat embedding-level caching.
Should load tests in CI/CD pipelines use production traffic replays or synthetic scenarios?
Both, at different tiers. Synthetic scenarios with parameterized data work best for commit-gate and nightly tests because they’re reproducible and fast. Production traffic replay, captured and sanitized, is better suited for pre-release validation because it reflects actual user behavior distribution. The catch with replay: you need a traffic capture pipeline that anonymizes PII and handles session-token regeneration, which adds infrastructure complexity. Start with synthetic; add replay when your Tier 3 release gate is mature.
What’s the minimum team investment to implement AI-augmented load testing effectively?
A single performance engineer can implement a Tier 1 CI/CD pipeline gate with AI-assisted script generation in approximately two weeks, including environment setup, script creation for three critical scenarios, threshold configuration, and pipeline integration. Expanding to Tier 2 and Tier 3 typically requires an additional 4–6 weeks and benefits from a second team member for test data management and results analysis workflow design. The ongoing maintenance investment drops significantly once self-healing scripting handles routine parameter drift.
Conclusion
AI-powered applications demand testing practices that match their architectural complexity. The DORA data is unambiguous: teams that adopt AI without robust testing mechanisms actively degrade their delivery stability [1]. The path forward isn’t more manual testing effort, it’s smarter automation that eliminates scripting backlogs, embeds performance gates directly in your delivery pipeline, and uses AI-driven analytics to surface the bottlenecks that averages hide.
The techniques covered here, intelligent script generation, self-healing maintenance, tiered CI/CD integration, and bias-aware simulation design, aren’t aspirational. They’re implementable with current tooling by teams willing to invest the two-to-six weeks needed to establish their first automated performance pipeline. Start with your three most critical user journeys. Define SLO-based thresholds. Automate the commit gate. Then expand. The elite performer differential, 127x faster lead time, 2,293x faster recovery [1], isn’t about having more testers. It’s about having smarter testing infrastructure.
References and Authoritative Sources
- DeBellis, D., Storer, K.M., Harvey, N., et al. (2024). 2024 DORA Accelerate State of DevOps Report (10th Annual Edition). Google Cloud. Retrieved from https://dora.dev/research/2024/dora-report/2024-dora-accelerate-state-of-devops-report.pdf
- National Institute of Standards and Technology. (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0), NIST AI 100-1. U.S. Department of Commerce. https://doi.org/10.6028/NIST.AI.100-1
- IEEE. (2024). Autonomous Load and Performance Testing with AI. IEEE Xplore, document 10549131. Retrieved from https://ieeexplore.ieee.org/document/10549131
- Beyer, B., Jones, C., Petoff, J., & Murphy, N.R. (Eds.). (2016). Site Reliability Engineering: How Google Runs Production Systems. Google. Retrieved from https://sre.google/sre-book/table-of-contents/
- National Institute of Standards and Technology. (2024). A Plan for Global Engagement on AI Standards, NIST AI 100-5. U.S. Department of Commerce. https://doi.org/10.6028/NIST.AI.100-5
- Cybersecurity and Infrastructure Security Agency. (2023). DevSecOps Fundamentals. U.S. Department of Homeland Security. Retrieved from https://www.cisa.gov/resources-tools/resources/devsecops-fundamentals


